RAG Architecture for Personal Website
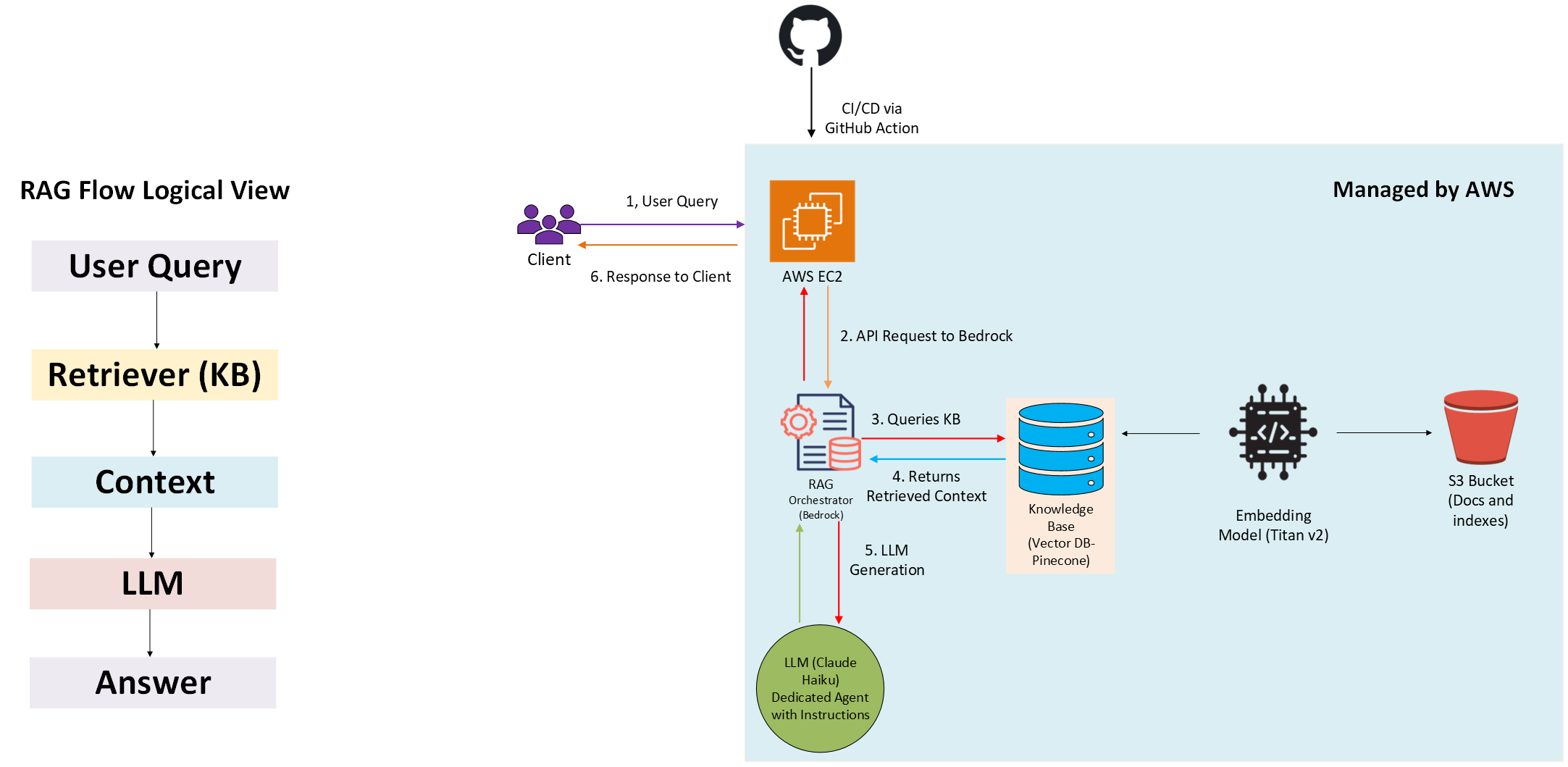
This project provides a technical description of a simple RAG (Retrieval-Augmented Generation) architecture I implemented on AWS for my personal website.
The site includes a chatbot that allows users to ask questions about my professional and academic background.
Architecture Overview
To build the website and chatbot, I used the following stack: GitHub (free), AWS (personal/paid), and Pinecone (free tier).
1. Application & Deployment
- The website is built with Next.js and hosted on an AWS EC2 instance.
- Nginx handles reverse proxying, and PM2 manages the Node.js process.
- GitHub Actions is used for CI/CD and automatic deployments.
2. Document Storage
Source documents (such as my resume and thesis) are stored securely in an AWS S3 bucket, with server-side encryption enabled.
3. RAG Workflow (via AWS Bedrock)
- AWS Bedrock handles orchestration for the RAG pipeline.
- When a user submits a query, Bedrock automatically queries the Knowledge Base (KB).
- In this setup, the KB is backed by Pinecone (used as a cost-effective option, but easily replaceable with AWS-native services).
- The KB returns relevant context, which is passed to the LLM to generate a coherent response.
- AWS Titan Text Embeddings v2 is used to embed the documents and store vectors in the KB.
The diagram below illustrates the full end-to-end flow.